I'm Building a Personal Recommendation Engine
I have so many things I want to play, read, or watch that I can't ever decide where to begin. So I thought, I can build that... and I did
I’ve talked about Mount Backlog before and while that project hasn’t quite gotten to where I want it to be, I still had a similar problem in that I had so many things that I wanted to play, read, watch, etc… that I could never quite know where to start. Sure I could pick something that sounded interesting to me or looked cool, or I could even just randomly pick something and dive in, but what if I had something that could consume all the information I already had available and make an informed choice on what I should play next?
Behold! “The Recommendinator”
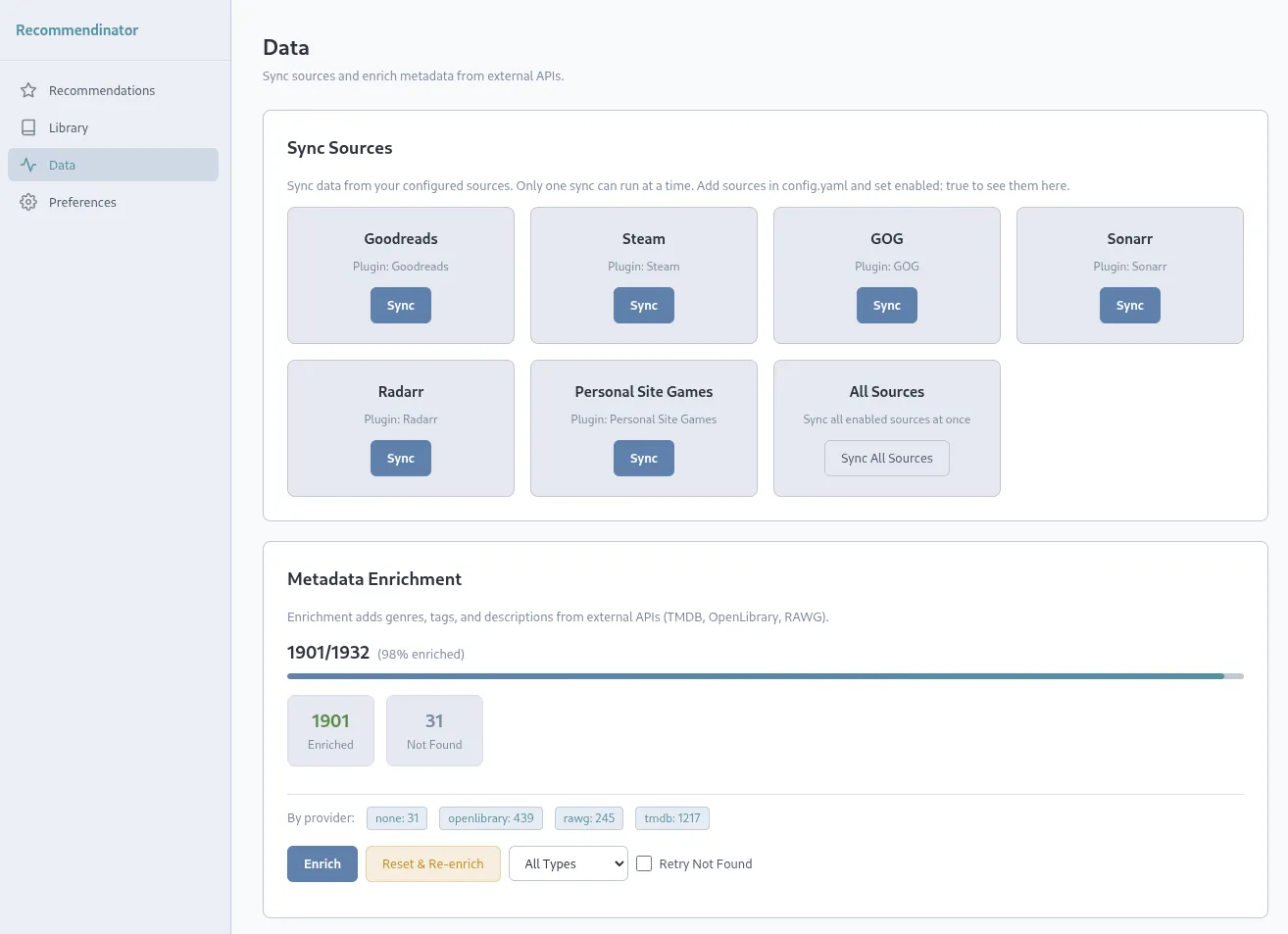
The Recommendinator is a system that is heavily plugin based so that you can import your data from a myriad of sources into a single cohesive database. While it’s currently finely tuned for my own individual needs, I built the ingestion system to be an extensible plugin system so that anyone could add their own ingestion plugins to meet their needs. Currently, it’s got some pretty standard defaults like JSON, CSV, and markdown support with supporting templates for you to leverage. I also have built an ingestion to work with Steam, GOG, Epic, the Goodreads export CSV as well as Sonarr and Radarr APIs. I also established a private plugin system so that you can build things that only you need specifically that don’t make sense for other people to use. For example, I have a private plugin that reads all my video game blogs from my personal site since it’s checked out on the same machine. It just parses everything and shoves it into the database. Not very helpful for anyone else, so private plugin it is!
Wait… did I just say I built an extensible plugin system? Why would I do that for something that I’m building for myself? Oh yeah baby, I’m open sourcing this sucker when it’s ready!
So how does this thing work? There’s currently two primary ways the system deals with configurations. YAML files and settings within the application. I envision that, in the future, everything will be controlled in the app but that’s later on down the line. But for now, the YAML file contains which features are enabled/disabled (more on that later), storage locations for databases, your ingestion inputs, enrichment sources, and a myriad of other configurations that will be explained in the example config.
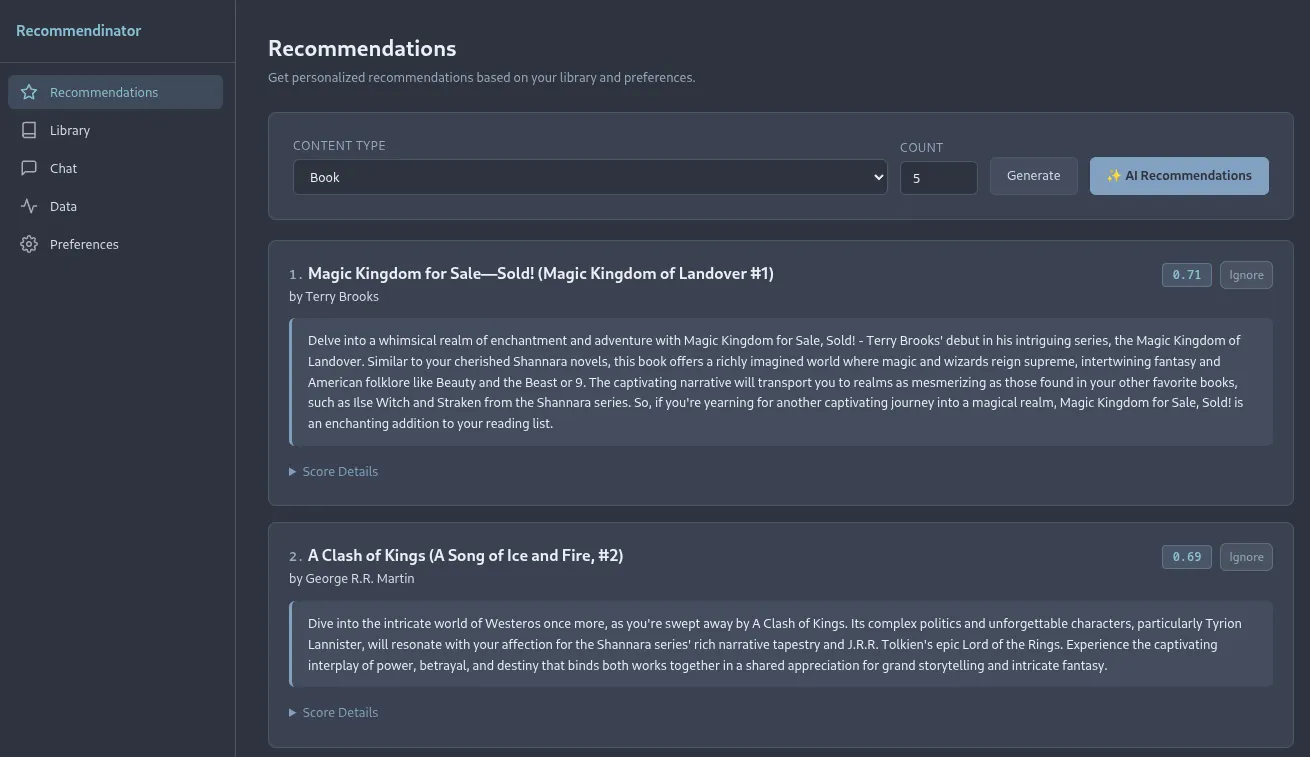
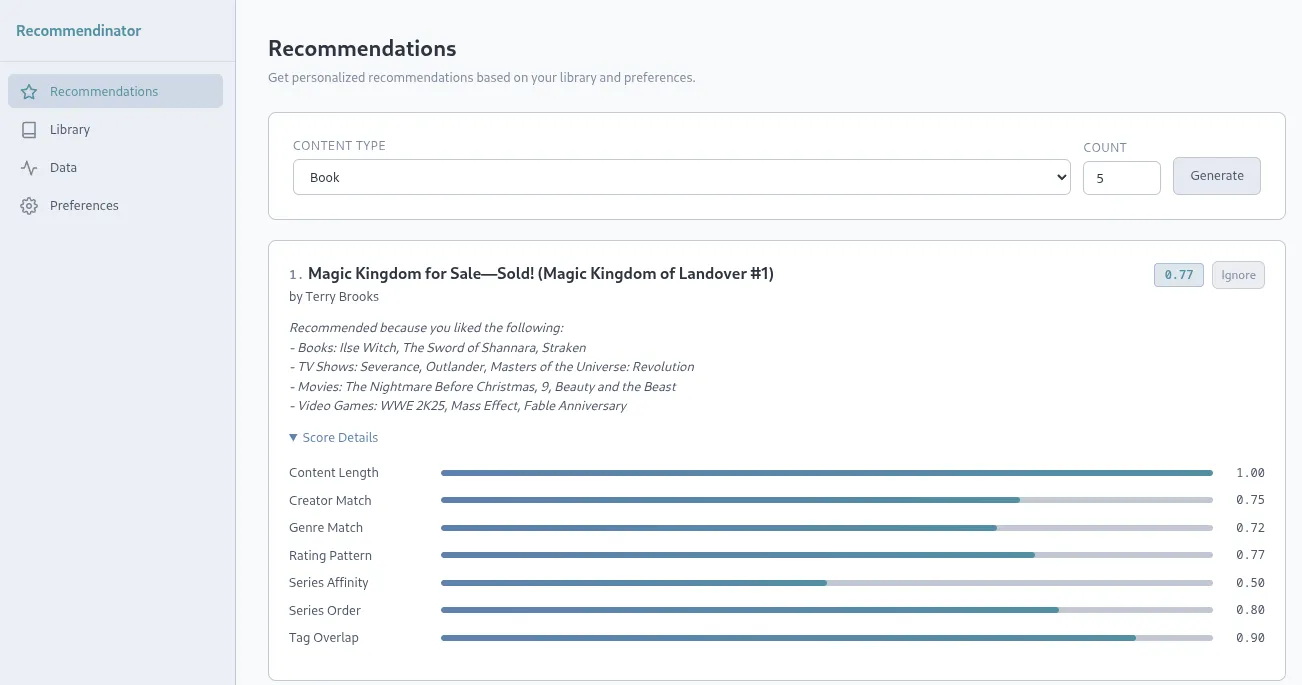
Inside the application, you can control things like weights for your recommendations. You can control how much being in the same genre matters, or the same creator, tags, how much consuming things in order (eg: book 1, then book 2, etc…) is important. You can force a few settings like “Recommend series in order” or “Variety after completion”. There are also length preferences where you can set things like short books, quick games, etc… and even a few natural language custom rules such as “avoid horror”, “prefer sci-fi”, etc…
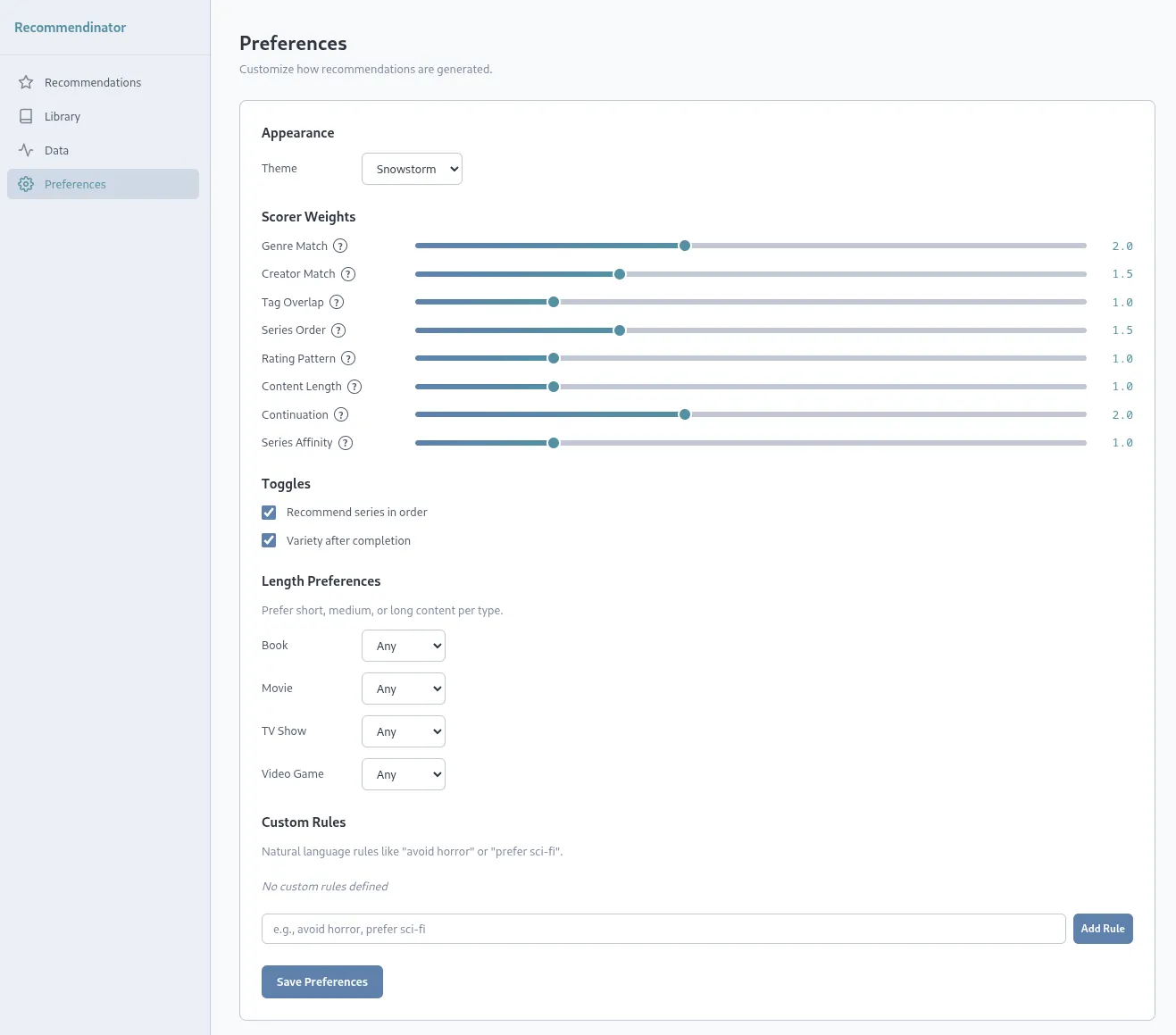
The first step, we’ve already covered is ingesting the data. From there, based on the enrichment sources you have setup in your configuration file, you can then further enrich the data. This is paramount in making sure that the recommendations end up being of any value. While some sources give rich metadata out of the gate, others are extremely limited or even non-existent. That’s where the enrichment piece comes in as it compares your data to known sources such as TMDB, RAWG, or OpenLibrary. Some will require you to get API keys in order to use but it’s highly recommended you do so.
The next bit to cover is where I think it’ll be divisive for some people, but hang on and read the next two paragraphs entirely before passing judgement. I tried to serve both communities here.
The entire thing is built with an AI off first approach. Even if you check out the repo and just new it up with docker, it doesn’t pull the ollama container, all the config files are set to disable AI by default, and none of the code paths require any AI functionality to be present in order to work. Period. I built this first and foremost without any AI functionality required and hyper tuned it to work to my expectations as a pure mathematical, weights, and algorithmic recommendations engine. THEN I layered on the additional AI pieces on top of it, but it will always be completely 100% usable without any AI items by default without any decisions having to be made by the user.
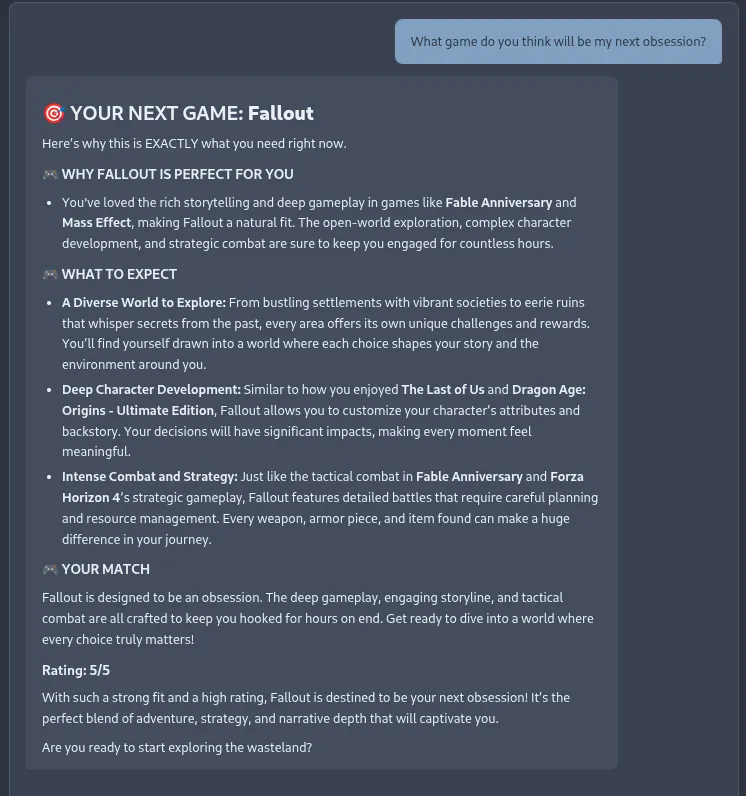
That being said, it does have full AI capabilities built in so that you can chat with the local model running on your machine (no training external LLMs with your data, you’re in control of it all). You can also enhance the reasonings on why a certain piece of content was recommended to you beyond just showing the score breakdowns and related titles. You’ll get back outputs that hopefully hype you up and make you feel excited to dive right into the recommendation. There’s still more tweaks I want to do here as the your profile section isn’t quite right yet as you’ll see it says I’m not into psychological thrillers or true crime, which is patently false. Also, it says I love war TV shows but not books, which is also incorrect. But hey, that’s how data works sometimes!
Oh, I need to update that screenshot so it shows “Chat with the Recommendinator” missed that one!
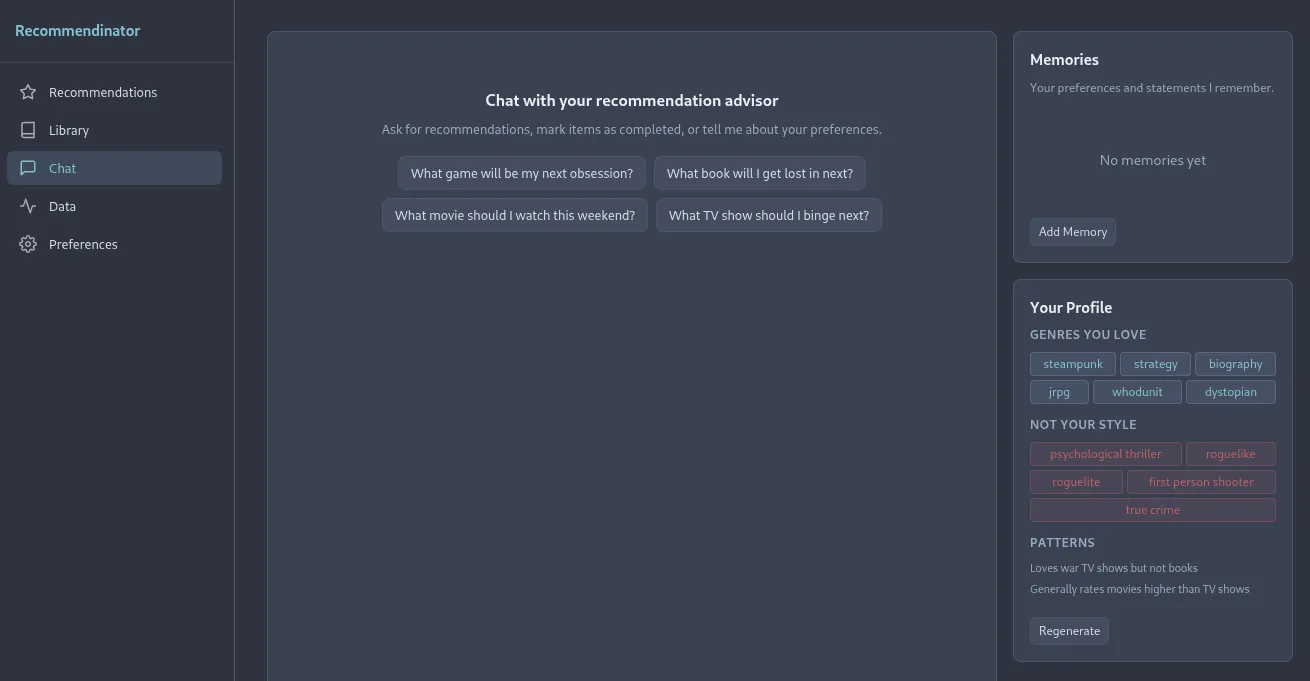 (more AI screenshots at the end of this post)
(more AI screenshots at the end of this post)
Hopefully that didn’t completely turn you off from the product, but hey, if it does, I get it. I took as much care to provide options here and if it’s not for you, it’s not for you.
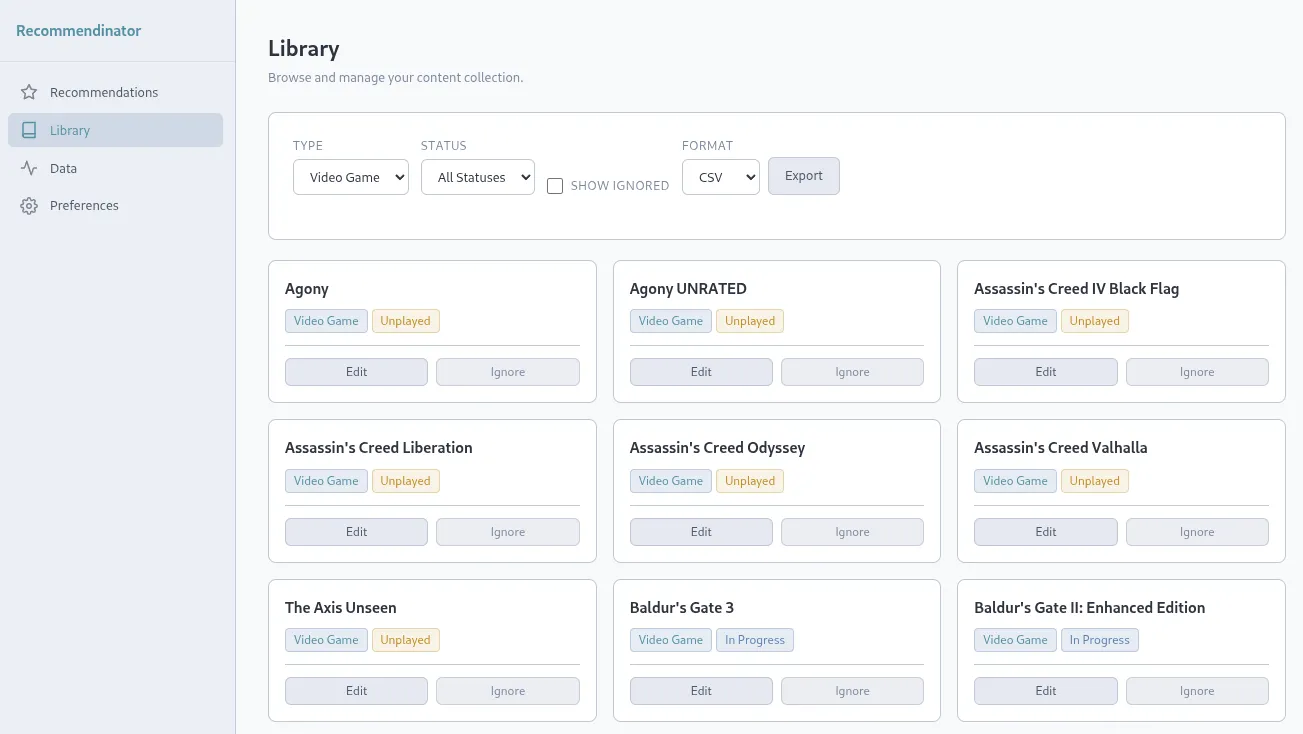
Finally, what good is any recommendation system if you can’t make fine-tuned adjustments of your library, well, that’s why I built out a full library management component of this. Now you can have all your sources syncing in (manually for now, automated coming later), but let’s say you just finished watching Season 2 of Fallout and you want to mark it complete so it stops recommending that to you. Fire up the Library, filter to TV shows, find Fallout, hit edit, check season 2, and hit save. Boom. If you have AI features enabled, you can also tell the chat that you finished Fallout Season 2 and give it a rating and it will update your data as well. Next time you ask for a recommendation, you’ll automatically get updated results based on the new additional data point the system has. It grows and learns with you so that it can be the best damn recommendation system you’ve ever used… or that’s my hope at least. Maybe it’ll be the most mediocre recommendation system you’ve ever used, that’s honestly probably a more realistic goal!
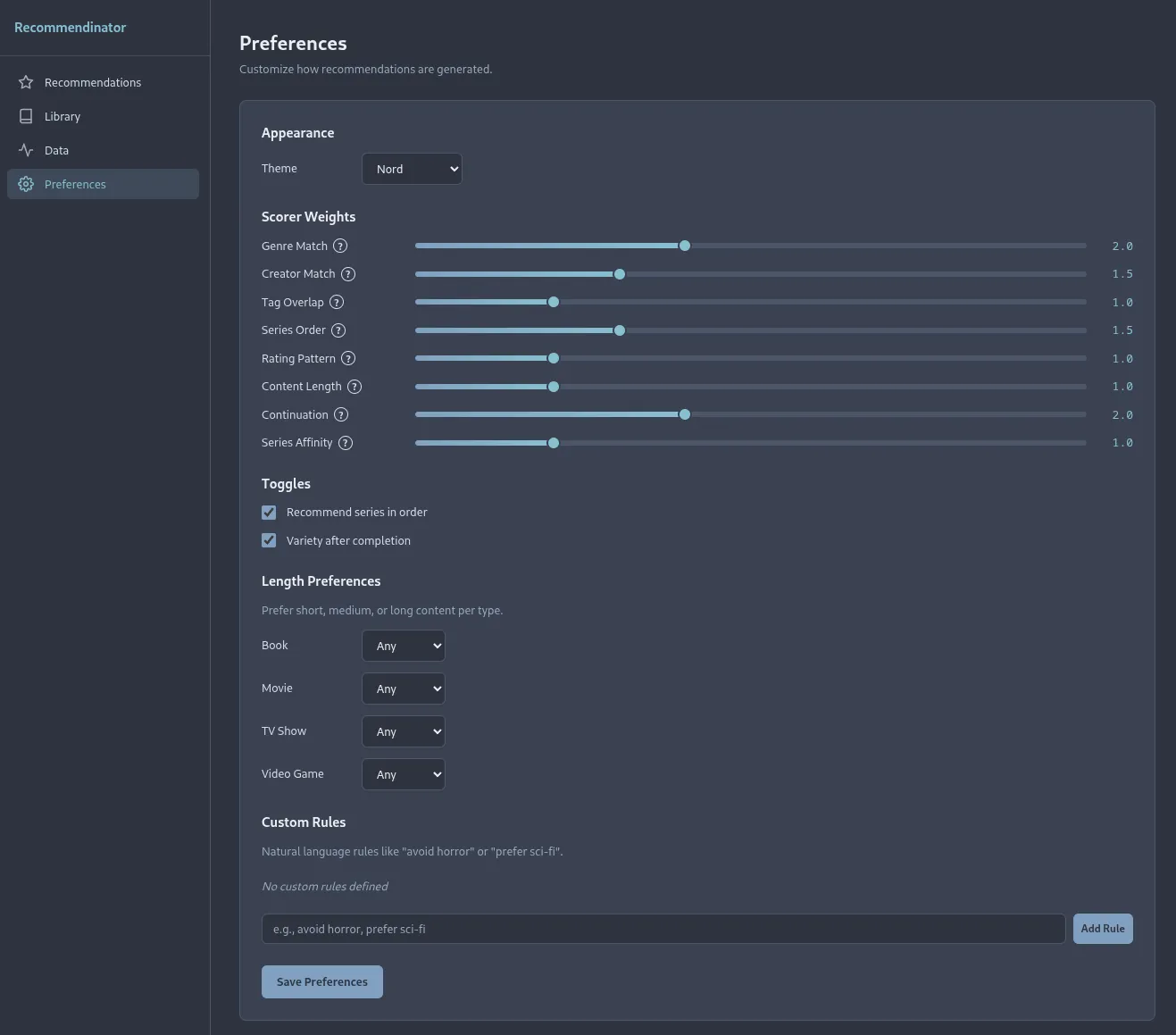
Oh, I almost forgot. I also built out a community driven theme system which you may have already noticed with the screenshots changing color schemes. So far I only have two themes, Nord and Snowstorm, but once this is available anyone can skin it to their liking and then open up a PR to share with everyone. Why should I prescribe how this looks when I’m not exactly the most skilled craftsman when it comes to UI and color palettes.
So that’s that, that’s what I’ve been working on for awhile now. It’s extremely close to being ready for release to the open world and then seeing where this thing goes. For now though, follow along on Mastodon as I’ve been posting about it a little bit here and there. Or if you’re excited by it and have any questions, comments, concerns, hit me up there and let me know what you think!
Additional AI Screenshots